Power CRM through Data Mining
Data mining tools and techniques
-------------------------------------------------------------------
Neural Networks:
Neural networks and decision trees can be used in building Classification models. Neural nets use many parameters (the nodes in the hidden layer) to build a model that takes and combines a set of inputs to predict a continuous or categorical variable.
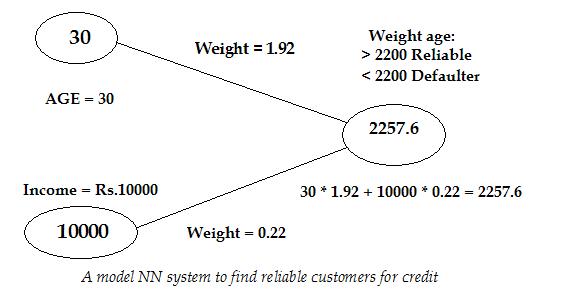
The value from each hidden node is a function of the weighted sum of the values from all the preceding nodes that feed into it. The process of building a model involves finding the connection weights that produce the most accurate results by "training" the neural net with data. The most common training method is back-propagation, in which the output result is compared with known correct values. After each comparison, the weights are adjusted and a new result computed. After enough passes through the training data, the neural net typically becomes a very good predictor.
Decision Trees:
Decision trees are classification tools that classify examples into finite number of classes considering one variable at a time and dividing the entire data set based on it. This can be used in inducing rules for classification and segmentation. Decision trees represent a series of rules to lead to a class or value.
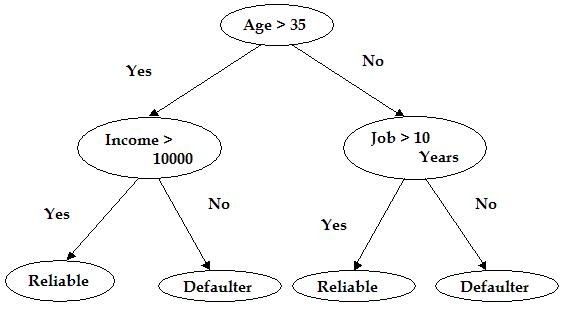
Decision trees have become very popular because they are reasonably accurate and, unlike neural nets, easy to understand. Decision trees also take less time to build than neural nets. Neural nets and decision trees can also be used to perform regressions, and some types of neural nets can even perform clustering.
Probability Rules:
Probability rules allow making logical "reaches" with assumptions about the data. They allow you to "impute" missing data into the data warehouse and therefore extend the range and reach of your knowledge.
For example, if a cool drink preference data for a set of newly acquired third-party prospect is missing and we have only age and gender, by mining the current data we can create a rule with high probability as follows: If customer age = 25 and customer gender = male, then cool drink preference = Coke. You can then impute that preference onto those customers when preparing promotions for the Coke preference profile.
Rule induction
Rule induction is one of the major forms of data mining and is perhaps the most common form of knowledge unearthing. It is a very special technique in sense it some times discovers a rule that is very interesting that tells something about the database that wasn’t already known or probably was tough to manipulate.
Rule induction on a data base can be a massive undertaking where all possible patterns are systematically pulled out of the data and then an accuracy and significance are added to them that tell the user how strong the pattern is and how likely it is to occur again. In general these rules are relatively simple such as for a market basket database of items scanned in a consumer market basket some interesting correlations in the database can be found such as:
If live plants are purchased from a hardware store then plant fertilizer is purchased 60% of the time and these two items are bought together in 6% of the shopping baskets.
Source: From the book "Building Data Mining Applications for CRM"
by Alex Berson, Stephen Smith, and Kurt Thearling
The rules that are pulled from the database are extracted and ordered to be presented to the user based on the percentage of times that they are correct and how often they apply.
The bane of rule induction systems is also its strength - that it retrieves all possible interesting patterns in the database. This is a strength in the sense that it leaves no stone unturned but it can also be viewed as a weakness because the user can easily become overwhelmed with such a large number of rules that it is difficult to look through all of them. A second pass of data mining is almost needed to go through the list of interesting rules that have been generated by the rule induction system in the first place in order to find the most valuable relation or rule amongst them all. These excessively available patterns might also overburden the task of prediction if two equally interesting rules produce conflicting predictions. However automating the process of pulling out the most interesting rule and framing the recommendations inferred out of the rules are well handled by many of the commercially available rule induction systems on the market. This is also an area of active research today.
Clustering:
Clustering is the method by which like records are grouped together. Usually this is done to give the end user a high level view of what is going on in the database. Clustering is sometimes used to mean Market segmentation.
Some examples are grouping the population by demographic information into segments that will be useful for direct marketing and sales. To build these groupings information such as income, age, Profession, location that is stored in the database can be used. Then to each cluster a name through which they can be recognized are assigned.
Nearest Neighbor
Nearest Neighbor prediction technique is one of the oldest techniques used in data mining. Nearest neighbor is a prediction technique that is quite similar to clustering - its essence is that in order to predict what a prediction value is in one record, look for records with similar predictor values in the historical database and use the prediction value from the record that it is “nearest” to the unclassified record.
Nearest Neighbor techniques are among the easiest to use and understand because they work in a way similar to the way that people think - by detecting closely matching examples. They are particularly adept at performing complex ROI calculations because the predictions are made at a local level where business simulations could be performed in order to optimize ROI. As they enjoy similar levels of accuracy compared to other techniques the measures of accuracy are
as good as from any other.
Next Page
HOME|Page 1|Page 2|Page 3|Page 4|Page 5|Page 7|Page 8